ScanSnap Evernote Editionはスキャンしたものを自動で振り分け、Evernoteへインポートしてくれます。その為、本を自炊する際にはちょっと注意が必要です。
というのもEvernoteはノートの最大容量が決まっているからです。
無料会員なら25MBまで。
プレミアム会員なら100MBまで。
(2013/11現在)
そこそこ綺麗な画質で画像の多い漫画などを自炊すると25MBくらいはすぐに超えてしまいます。

ただこの機種の場合、購入すれば1年間のプレミアム会員権が付いてくるので大抵のユーザーは100MBのファイルまではインポート可能。だからそんなに深く考えなくてもいいのかも。
どちらにしても、ベースがScanSnap iX500なので自炊する事自体には問題はありません。
そこで今回ちょっと容量が大きくなりそうな書籍を自炊してみました。
準備とScanSnap Managerの設定
自炊してみたのはこちらの一冊。


でもよく考えてみると、この本はkindle版も出ているので最初からそっちを買った方が自炊するより手間がかからなくていいのかも・・・
それはさておき。
ScanSnap Managerの設定はほぼデフォルトのままで、画質だけスーパーファインにしています。「検索可能なPDFにする」にはチェック。
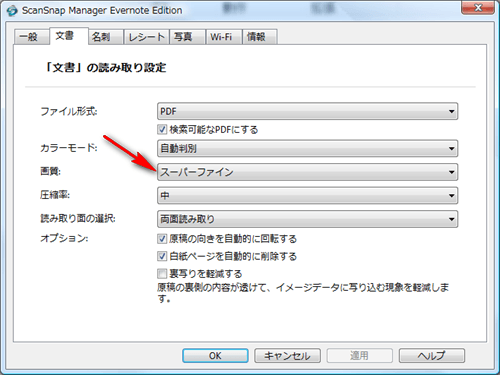
ScanSnap Evernote Editionを開いて。

原稿をセット。

スキャン
ScanSnap EvernoteEditionの原稿搭載できる最大数が50枚。
なので全ページは載せられない為、継ぎ足しつつスキャンします。

全ページスキャンが終わるとこのような画面が表示されます。
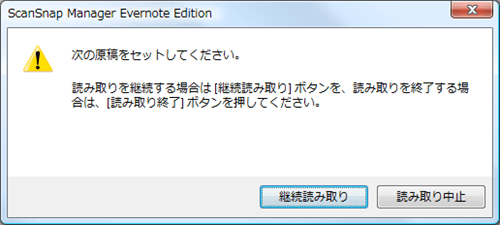
終了する場合は「読み取り終了」ボタンを押してください。と書かれていますが、そのボタンが見当たりません。
でも「読み取り中止」ボタンを押すとちゃんと終了します。
もしかして自分が気付いていないだけでどこかに「読み取り終了」ボタンがあるのかもしれないです。
本の内容はこのように文章と写真が入り交じっているものですが、普通に文書と認識されて振り分けられました。

問題なくEvernoteへインポート済み。
ここまで自動で進みます。(ノートタイトルは手作業で変えています)
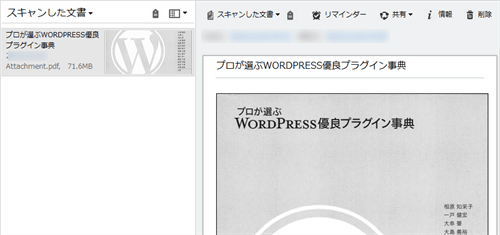
中身も問題無し。

ページ数が209ページ、容量にして71.5MBのファイルかつWi-Fi接続という環境でしたが、スキャン開始→Evernoteに格納までさほど時間はかかりませんでした(処理時間はPCの性能によるかも)。
その他
なんとなく1点だけ注意点というか何というか。
現時点(2013/11)でEvernote上では、PDFファイルが1ファイル25MB、ページ数が100ページを超えると自動OCR認識されません。
これはプレミアム会員であったとしてもです。(というかプレミアム会員でなければそもそもOCRの自動処理が行われないですね。)
→Evernote ナレッジベース | 画像ベースのPDFがテキスト検索用にインデックス化されていないのはなぜですか?
100ページを超えるPDFファイルの中身をEvernote上で文字検索できるようにしたい場合は、事前にOCR処理を施しておく必要があります。
この点ScanSnap Evernote Editionであれば「検索可能なPDFにする」にチェックをいれておくと、自動でOCR処理した上でEvernoeへ保存してくれます。

あまり何も考えなくてよく、非常に楽です

